 선착순 모집! 국비지원 받고 4주 완성
선착순 모집! 국비지원 받고 4주 완성
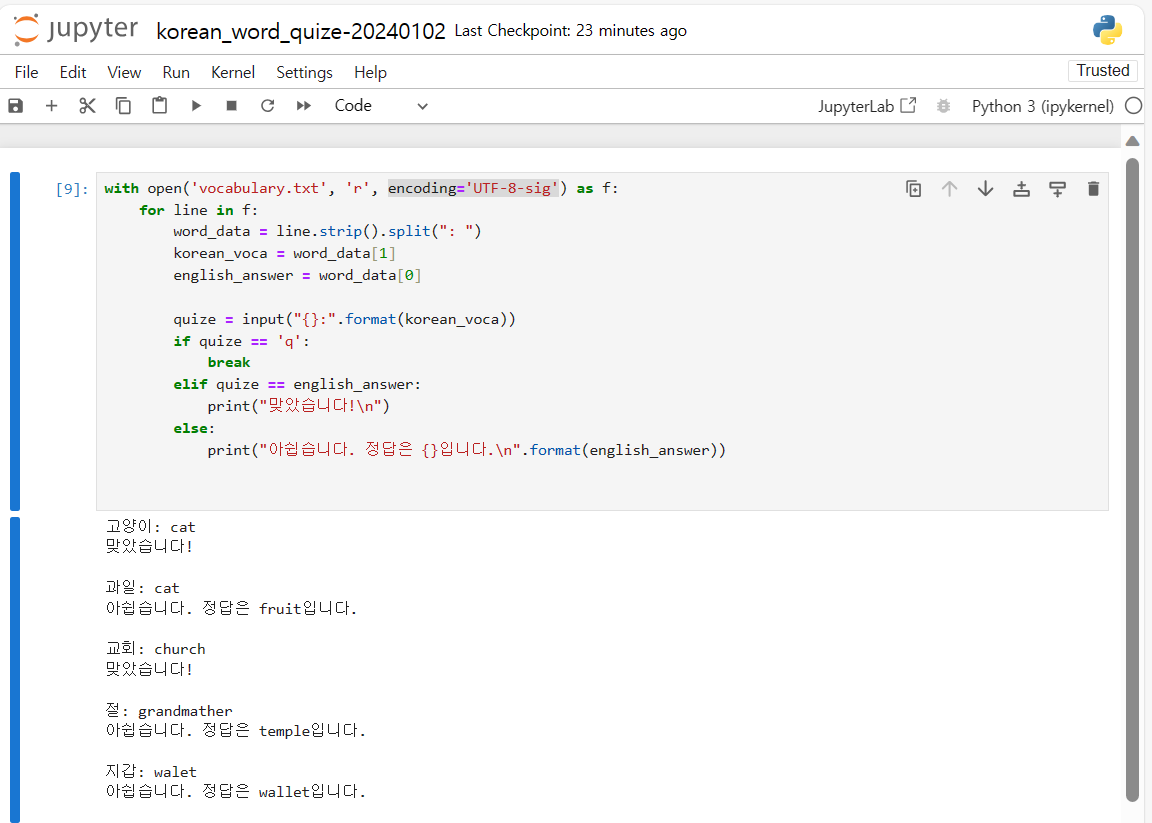
인코딩 #\ufeff 문제가 발생하여 cat을 cat이라고 해도 정답처리가 안됩니다
질문 지켜보기
cat을 cat이라고 해도 오류가 발생하길래 아래의 방법으로 해결하긴 했습니다.
고양이: cat
아쉽습니다. 정답은 cat입니다. #라고 나와서 오류의 존재를 발견했습니다.
in_file = open("vocabulary.txt", 'r', encoding='utf-8') #\ufeff문제 발생원인입니다.
for line in in_file:
korea_word = line.strip().split(': ')[1]
answer = line.strip().split(': ')[0]
print(line.strip().split(': ')) # 이걸 쳐서 오류가 어떻게 발생하고 있다는 걸 알아차렸습니다.
question = input("%s: " % korea_word)
if question == answer:
print("맞았습니다!")
else:
print("아쉽습니다. 정답은 %s입니다." % answer)
in_file.close()['\ufeffcat', '고양이'] #보시면 txt파일에는 없는 \nfeffcat가 나옵니다. 그래서 cat을 입력하면 틀린다는 것 같은데 /nfeffcat라고 쳐도 똑같이 틀립니다.
고양이: cat
아쉽습니다. 정답은 cat입니다.
['apple', '사과']
사과: apple
맞았습니다!
['church', '교회']
교회: church
맞았습니다!
['temple', '절']in_file = open("vocabulary.txt", 'r', encoding='utf-8-sig') #\ufeff문제로 -sig를 하니 문제 해결했습니다.
------------
['cat', '고양이']
고양이: 인터넷에 검색해보니 https://redcarrot.tistory.com/216
에서 -sig를 하라고 해서 하니 정말 문제가 해결이 되었습니다.
어떤 문제가 있는 것이고 왜 이런 오류가 발생하나요?
+0
A
1개의 답변이 있어요
저도 같은 문제로 고민하고 있었는데, 가르쳐주신 대로 encoding='UTF-8-sig'을 하니 정답으로 나옵니다.
감사합니다.
참고로, 저는 Jupyter Notebook에서 작성하였습니다.
2024년 1월 2일
+0
댓글 4개